
RDS で、大量のIO を伴う処理を行うと、処理途中で性能が大きく劣化することがあります。
不要になった大量の過去データをバッチで削除する時によく発生します。
これは、ストレージへの IO を規定量より高い頻度で行った時に減少するクレジットがあり、それが 0 になった時、パフォーマンスに制限がかかってしまうためです。
制限のかかった状態では通常通りのサービス運用はできなくなってしまうため、過去データ削除などの高負荷のバッチは、RDSのモニタリングページを見ながら注意深く実施する必要があります。
今回は、パフォーマンス低下を避けるために確認すべき RDS クレジットのメトリクスについて書きます。
各メトリクスの詳細は、AWS の公式ドキュメントに詳細な解説があります。
高負荷な処理を行う際に確認すべきメトリクス
EBS Byte Balance
AWS のドキュメントによると、「RDS データベースのバーストバケットに残っているスループットクレジットの割合。」とのこと。データ転送量で減少していくのでしょうか。重い SQL を実行することで減ることがあります。
0になるとパフォーマンスが大幅に劣化します。
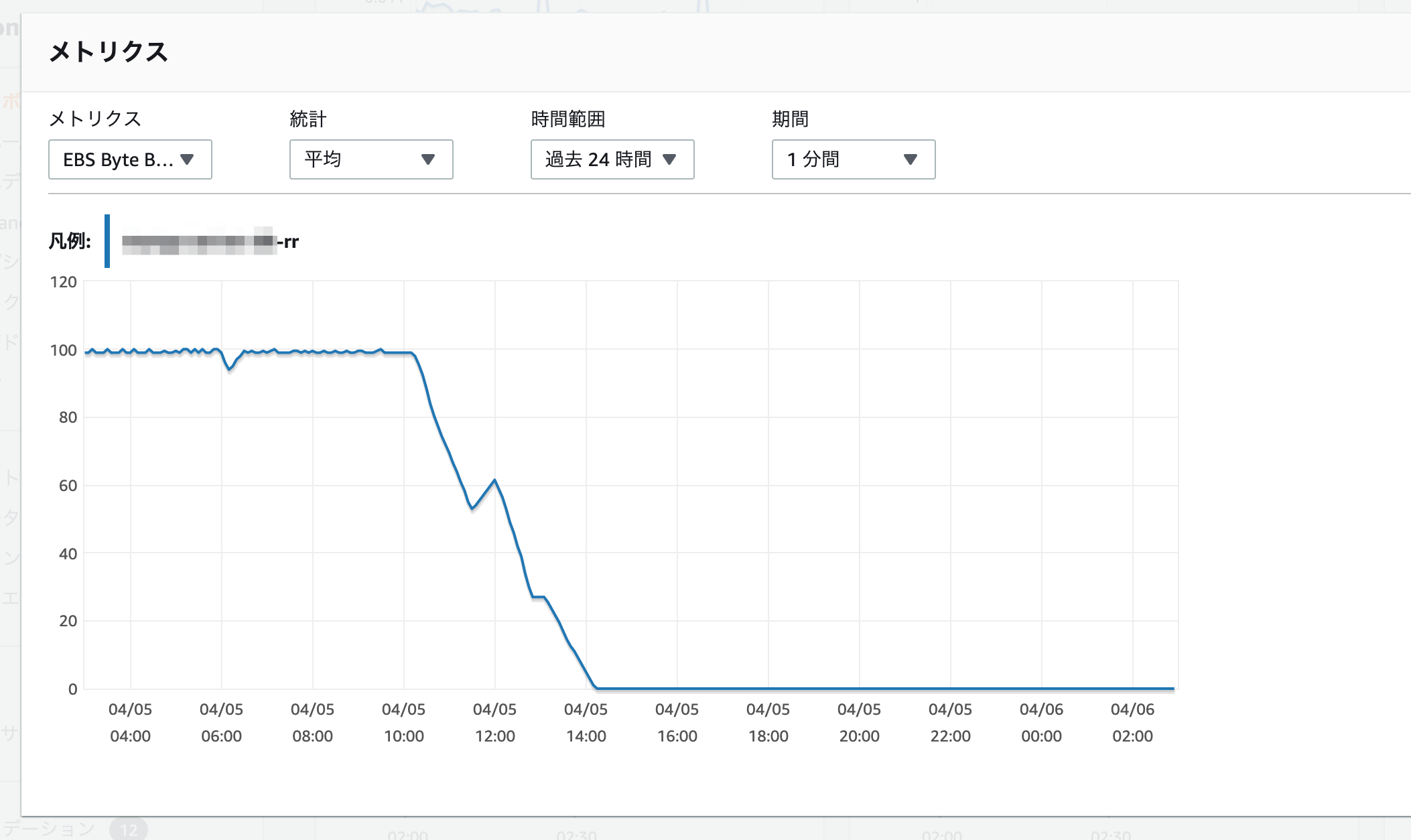
クレジットを消費するような SQL を実行しなければ、自動的に回復します。
EBS IO Balance
AWSドキュメントによると「RDS データベースのバーストバケットに残っている I/O クレジットの割合。」とのこと。広範囲の DELETE 文など、 IO が多く発生する SQLを実行するとどんどん減っていき、0になるとパフォーマンスが大幅に劣化します。クレジットを消費するような SQL を実行しなければ、自動的に回復します。

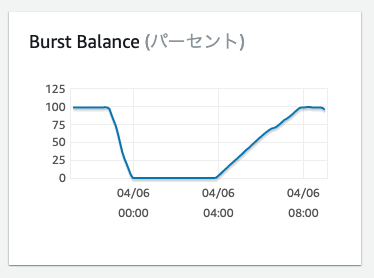
Burst Balance
AWSドキュメントによると「汎用 SSD (gp2) のバーストバケット I/O クレジットの利用可能パーセント。」プロビジョンド IOPS の RDSには項目がありません。GP2 ストレージの場合に、広範囲の DELETE 文など、 IO が多く発生する(IOバーストがされる) SQLを実行すると減っていきます。
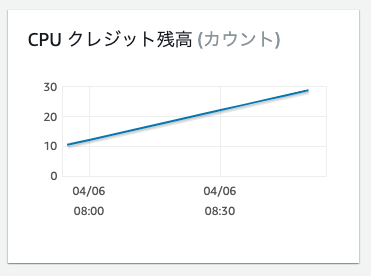
CPU クレジット残高
T系インスタンスの場合にあります。CPUを多く使う(CPUバーストがされる)処理を行うと減っていき、0になるとパフォーマンスが大幅に劣化します。T系のEC2とお使いであれば、おなじみの項目ですね。
バイナリログのディスク使用状況とリードレプリカのレプリケーション遅延
リードレプリカをマスターより低い性能で運用している場合、マスターで行った処理を同じ速度で処理することができず、レプリケーション遅延が発生することがあります。
この時、リードレプリカが処理できないバイナリログはマスターの RDS に蓄積されるため、バイナリログのサイズが溜まっていき、リードレプリカの遅延もどんどん大きくなります。
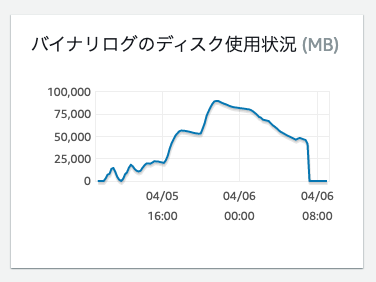
解消させるにはマスターの処理のペースをリードレプリカに合わせて減らすしかありません。
状況に気づかずに大きな遅延とバイナリログができてしまった場合、遅いリードレプリカの処理を待つより、一度リードレプリカを削除し、新たに作り直したほうが時間短縮になる場合があります。
まとめ: 高負荷な SQL を発行する時に気をつけること
クレジット消費で一番やりがちなのは DELETE 文で多くのレコードを消そうとした場合です。また、その DELETE で変更されたストレージを最適化させるための OPTIMIZE TABLE でも多くのクレジットが消費されることがあります。
DELETE を行う場合、量にもよりますが、一発で済まそうとせず、範囲を絞って何度か実行するような SQLでメンテナンスしたほうがトラブルを避けられます。また、範囲指定もインデックスを使うようにし、意図しない広範囲のロックを避ける必要があります。
OPTIMIZE TABLE は範囲を絞ることはできないため、メトリクスを監視しながら、クレジットが 50% を切るようであれば停止を検討したほうが良いでしょう。
OPTIMIZE TABLE に限らず、10分以上かかるSQL の場合は、AWSコンソールから上記 EBS Byte Balance 、EBS IO Balance、 Burst Balance、 CPU クレジット残高、バイナリログのディスク使用量、またリードレプリカの遅延 のメトリクスを常に監視し、クレジットの使い切りを発生させないようにしてください。