
前提
S3 Glacier
S3 Glacier は、AWS のバックアップデータの保存サービスです。
What Is Amazon S3 Glacier? - Amazon S3 Glacier
以前は Glacier というサービス名でしたが、いつからか S3 Glacier という名前に変わりました。
S3 などのストレージを安価にアーカイブ(バックアップ)することができます。S3 以外にも、外部から API で送った内容をアーカイブできます。
ファイル名という概念は無く、送ったデータがアーカイブされた際は「アーカイブID」が付与されます。取得するにはアーカイブIDが必要です。
アーカイブしたり複合したりするには1アクションにつき5時間ぐらいかかります。
SynologyのNAS
Synology の NAS は Web UI からアプリをインストールできるようになっており、Glacier Backup というアプリがインストールできます。
Glacier Backup アプリ

Synology の NAS にインストールした Glacier Backup を使うと、NAS を AWS S3 Glacier に定期的にバックアップすることができます。
また逆に、Glacier から NAS に内容すべてを復元することもできます。
すべて Web上のUIで行えるため、手軽でいいのですが、ファイル単位での復元ができません。
復元時間
100GB程度のNASであれば、復元に2日ぐらいかかると思って良いでしょう。 テラバイト規模の場合は1ヶ月単位での復旧期間がかかりそうです。
アーカイブの構造
Glacier Backup のアプリは、2つのボールトを AWS S3 Glacier 内に作ります。
メインとなるファイルの内容をすべて保存するボールトが1つと、メインのアーカイブのファイルのフルパス名の対応表を格納している _mapping という文言が名前の末尾につくボールトが1つ作られます。
_mapping のボールトには、ファイルのフルパス名とアーカイブIDの対応表が SQLite3 形式で保存されています。
今回の要件
Synology の Glacier Backup アプリでバックアップしたボールトから、特定の1ファイルだけを復元します。
復旧手順
1. マッピングのボールトのアーカイブ一覧を取得 (InventoryRetrieval)
AWS CLI で、_mapping のボールト内のアーカイブ一覧を取得します。
aws glacier initiate-job --account-id 012345678901 \
--vault-name my_synology_0011223344FF_1_mapping \
--job-parameters="{\"Type\":\"inventory-retrieval\"}"
実行すると、以下のような JSON がレスポンスされます。
{
"location": "/012345678901/vaults/my_synology_0011223344FF_1_mapping/jobs/<job-id-here>",
"jobId": "<job-id-here>"
}
上記の <job-id-here> の箇所にジョブIDが入っています。
試しに、ジョブの内容を取得します。
aws glacier describe-job --account-id 012345678901 \
--vault-name my_synology_0011223344FF_1_mapping \
--job-id <job-id-here>
{
"JobId": "<job-id-here>",
"Action": "InventoryRetrieval",
"VaultARN": "arn:aws:glacier:ap-northeast-1:012345678901:vaults/my_synology_0011223344FF_1_mapping",
"CreationDate": "2023-10-30T00:25:25.289Z",
"Completed": false,
"StatusCode": "InProgress",
"InventoryRetrievalParameters": {
"Format": "JSON"
}
}
まだ処理中のようです。
処理には5時間程度かかるので、待ちます。
ちなみに処理が終わってから24時間経過するとジョブの結果は消えてしいますので注意してください。
2. Inventory Retrieval ジョブの結果を取得する
5時間経過したら、ジョブの結果を再取得してみます。
aws glacier describe-job --account-id 012345678901 \
--vault-name my_synology_0011223344FF_1_mapping \
--job-id <job-id-here>
{
"JobId": "<job-id-here>",
"Action": "InventoryRetrieval",
"VaultARN": "arn:aws:glacier:ap-northeast-1:012345678901:vaults/my_synology_0011223344FF_1_mapping",
"CreationDate": "2023-10-30T00:25:25.289Z",
"Completed": true,
"StatusCode": "Succeeded",
"CompletionDate": "2023-10-30T04:06:58.738Z"
"InventoryRetrievalParameters": {
"Format": "JSON"
}
}
ジョブが終わっていました。
3. ジョブの結果を取得する
さきほど終了したジョブの内容を表示します。
aws glacier get-job-output --account-id 012345678901 \
--vault-name my_synology_0011223344FF_1_mapping \
--job-id <job-id-here>
{
"VaultARN":"arn:aws:glacier:ap-northeast-1:012345678901:vaults/my_synology_0011223344FF_1_mapping",
"InventoryDate":"2023-10-28T21:59:35Z",
"ArchiveList":[{
"ArchiveId":"<mapping-archive-id-here>",
"ArchiveDescription":"",
"CreationDate":"2023-10-28T17:25:18Z",
"Size":76182528,
"SHA256TreeHash":"..."
}]
}
このボールトにはアーカイブが1つだけ含まれていることがわかります。これが SQLite3のデータベースのファイルがアーカイブされたものです。
4. マッピングファイルを取得可能にする (ArchiveRetrieval)
さきほど取得した <mapping-archive-id-here> のアーカイブIDに対して archive-retrieval ジョブを発行し、アーカイブのファイルを取得可能にします。
aws glacier initiate-job --account-id 012345678901 \
--vault-name my_synology_0011223344FF_1_mapping \
--job-parameters="{\"Type\":\"archive-retrieval\", \"ArchiveId\":\"<mapping-archive-id-here>\"}"
表示されたジョブIDを記録しておきます。
実行後、5時間待ちます。
5. マッピングファイルを取得する
さきほどと同様に aws glacier describe-job を行い、"Completed" が true となっていることを確認後、get-job-output でファイルの内容を取得します。
aws glacier get-job-output --account-id 012345678901 \
--vault-name my_synology_0011223344FF_1_mapping \
--job-id <さきほどのジョブID> ${HOME}/Downloads/my_synology_mapping.sqlite3
6. マッピングファイルの内容を見て、ファイル名と対応するアーカイブIDを検索する
sqlite3 ${HOME}/Downloads/my_synology_mapping.sqlite3
とすることで内容を確認できます。 DataGrip など GUI クライアントがあれば、そちらで開きましょう。
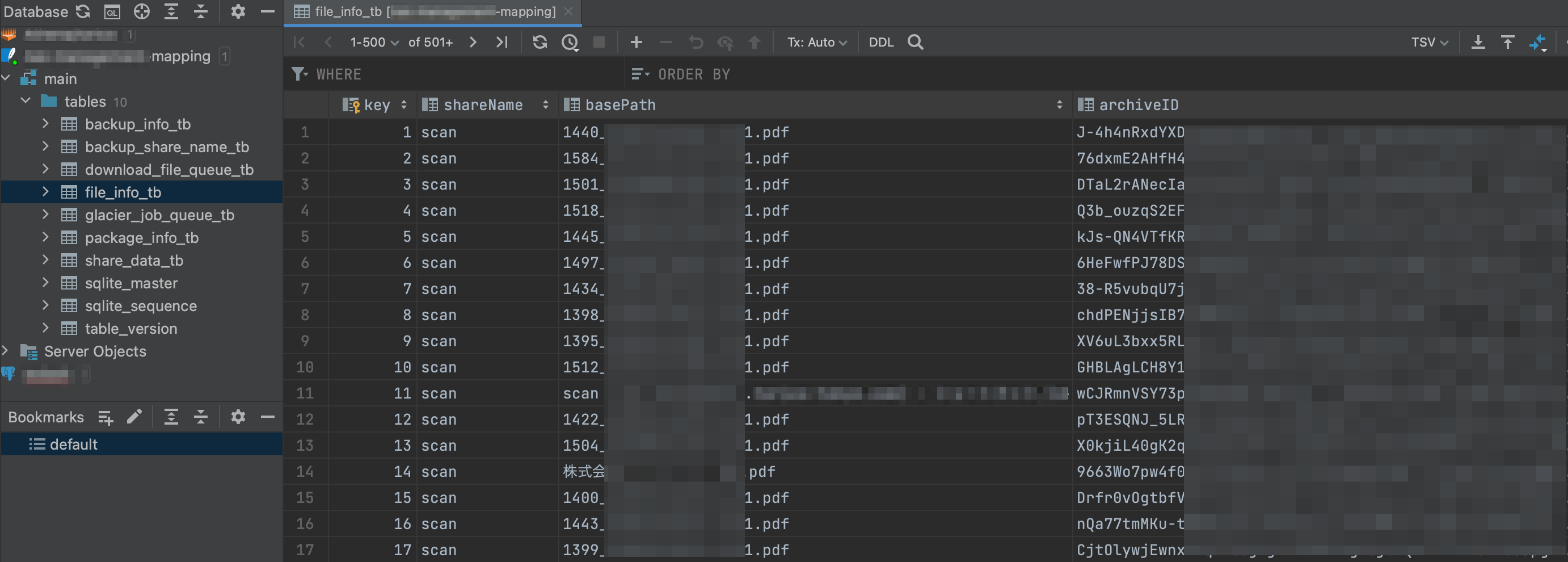
file_info_tb テーブルに、ファイルのフルパスとアーカイブIDの対応表が入っています。 ファイル名で SELECT し、該当する アーカイブIDを検索してください。
7. 目当てのアーカイブを取得可能にする
取得するアーカイブに対して archive-retrieval ジョブを発行し、ファイルを取得可能にします。
対象とするボールトは、 _mapping がつかない方です。
aws glacier initiate-job --account-id 012345678901 \
--vault-name my_synology_0011223344FF_1 \
--job-parameters="{\"Type\":\"archive-retrieval\", \"ArchiveId\":\"<復元対象のアーカイブID>\"}"
他にも取得するファイルがあるなら archive-retrieval を発行しておきましょう。
実行後、5時間待ちます。
8. 目当てのファイルを取得する
aws glacier describe-job を行い、"Completed" が true となっていることを確認後、get-job-output でファイルの内容を取得します。
aws glacier get-job-output --account-id 012345678901 \
--vault-name my_synology_0011223344FF_1 \
--job-id <さきほどのジョブID> ${HOME}/Downloads/取得するファイル名
ファイル名はボールト内に保存されていないため、先程の mapping の SQLite3のデータベースの file_info_tb に保存されているファイル名を自分で付与します。