サーバでSSHの通信断してもバッチを動かし続けるため、tmux を使うと便利。nohup より
2018.03.13 09:53 (8年前) 投稿者: カテゴリ: linux
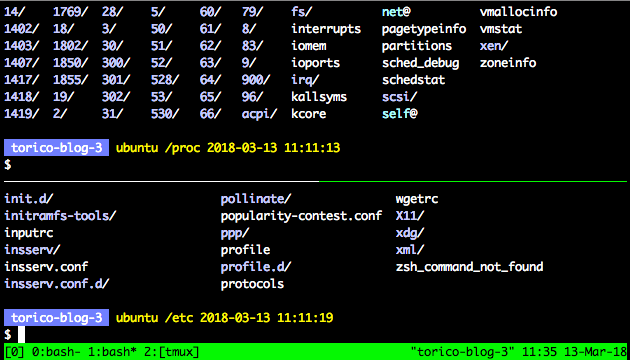
tmux という、CUI (TUI) 用仮想スクリーンアプリケーションがあり、SSH 越しに Linux を操作する際大変便利です。似たようなものに byobu とか screen がありますが、私は tmux が好きで、よく使います。 便利に使うスクリプト Linux でのシェル起動時、 (.bashrc 等) 下記のスクリプトを起動しています。